CASE STUDY 01 · AI · Live Video
Cue
A live video interview with an AI that watches, listens, and scores.
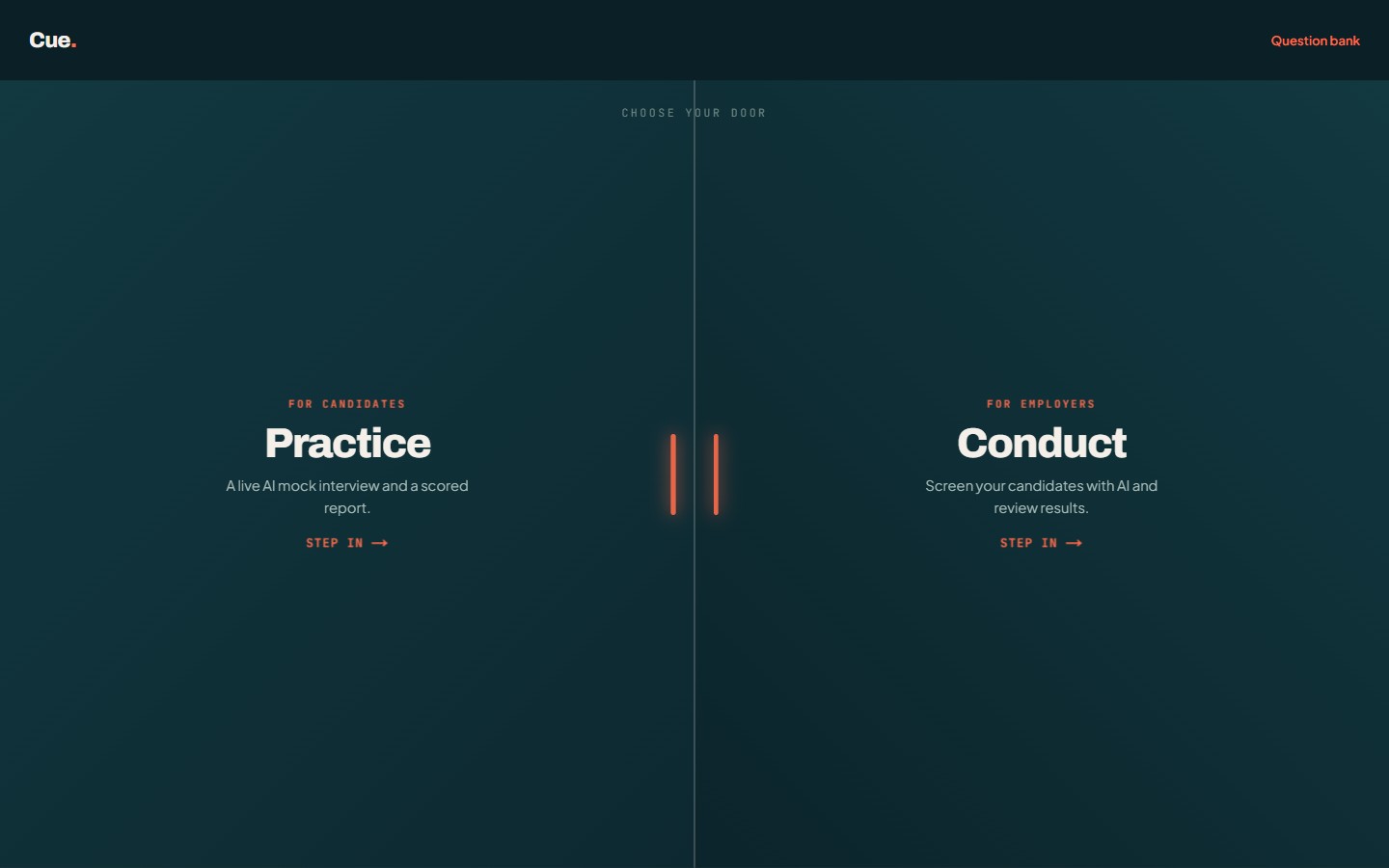
Two doors: candidates practice with a live AI mock interview and get a scored report; employers screen real candidates with AI and review the results. Spoken questions, camera on, verdicts across content, vocal delivery, body language, and integrity.
2
modes — practice & employer screening
4
scoring channels (content, voice, body, integrity)
~real-time
spoken turn latency via Gemini Live
5
tailored questions per session
THE PROBLEM
Interview practice tools are either question banks you read silently or expensive human mock interviews. Neither reproduces the thing that actually fails people: performing an answer out loud, on camera, under time pressure, while someone evaluates you.
The technical bar is what kept this category thin — you need real-time video, an AI that can hold a spoken conversation with acceptable latency, and evaluation that goes beyond transcribing words.
WHAT I BUILT
A full interview loop behind two doors. Practice: a candidate picks a role or pastes a JD, gets five tailored questions, and runs a live video session where an AI interviewer asks them aloud and listens to spoken answers in real time. Conduct: employers set up screening rounds from a question bank, send candidates a link, and review AI-scored results.
Evaluation happens on multiple channels at once — what was said (content), how it was said (vocal delivery), what the camera saw (body language via on-device pose/face tracking), and session integrity signals like tab switches and off-screen glances. The result is a scored report with per-question breakdowns, exportable as a PDF.
ARCHITECTURE
browser (candidate)
├─ camera/mic ──► LiveKit room (self-hosted SFU)
│ │
│ ▼
│ agent worker (Python)
│ ├─ Gemini Live ◄─ spoken Q&A, low-latency
│ └─ scoring pipeline ─► report + PDF
└─ MediaPipe (on-device)
└─ pose/face signals ──► integrity + body-language score- LiveKit runs on the same VPS as everything else — the SFU, the agent worker, and the web app are one deployable unit behind Caddy.
- Body-language analysis runs on-device with MediaPipe: raw video never leaves the browser for that channel, only derived signals do. Cheaper, faster, and better for privacy in one move.
- The agent is a LiveKit Agents worker: it joins the room like a participant, streams audio to Gemini Live for conversational turns, and accumulates evaluation state across all five questions.
STACK — AND WHY
Next.js 16
App shell, report pages, and PDF export route.
LiveKit
Self-hosted SFU + agent framework — full control over rooms and media, no per-minute vendor bill.
Gemini Live
Low-latency spoken conversation; the interviewer has to respond like a person, not a chatbot with a spinner.
MediaPipe
On-device pose and face tracking for body-language and integrity signals without shipping video to a server.
Python + FastAPI
Agent worker and scoring pipeline.
THE HARD PARTS
Conversational latency is the product
An interviewer that pauses three seconds before every follow-up destroys the illusion. Getting the turn loop tight meant streaming audio into Gemini Live and keeping every scoring computation off the hot path — evaluation accumulates in the background and only finalizes after the session.
Scoring what isn't in the transcript
Content scoring from a transcript is easy. Vocal delivery and body language required separate channels with their own pipelines — prosody features from audio, pose/gaze signals from MediaPipe — then calibrating channel weights so the final score feels fair rather than arbitrary.
Five tailored questions from an arbitrary JD
Pasted job descriptions range from two lines to two pages of boilerplate. The question generator has to extract what the role actually tests and produce five questions with escalating difficulty — robust to garbage input, because users paste garbage.
WHAT IT TAUGHT ME
- Latency budgets are product decisions, not infrastructure details. Every feature that touched the live loop had to justify its milliseconds.
- On-device ML (MediaPipe) turned the hardest privacy question — 'where does my interview video go?' — into a non-issue for an entire scoring channel.
- Self-hosting LiveKit was the right call: the per-minute pricing of hosted video APIs makes a free practice tool economically impossible.